“Team, We Are Faster than Siri!”
Challenge:
Our speech recognition takes up to 3 seconds or more until a word appears on the screen.
Approach:
Impress upon engineers why this is too slow and how we can make it faster together.
Contribution:
Product Designer and Product Manager
Year: 2016
Situation
When AppTek speech recognition technology debuted, it recorded the audio data, sent it to the servers, and then sent it back to the device as text. The ability to send text back while still recording / speaking was one of the relatively new features that made a voice assistant like DIVA possible in the first place. The crux was that it took 2.7 seconds or more until the uttered word was displayed on the device, which made the interface feel sluggish.
Especially when it was compared to other voice recognition systems. Back then the team was not aware that this might be too slow for the user. It “worked” and there were other problems the team needed to solve.
Approach
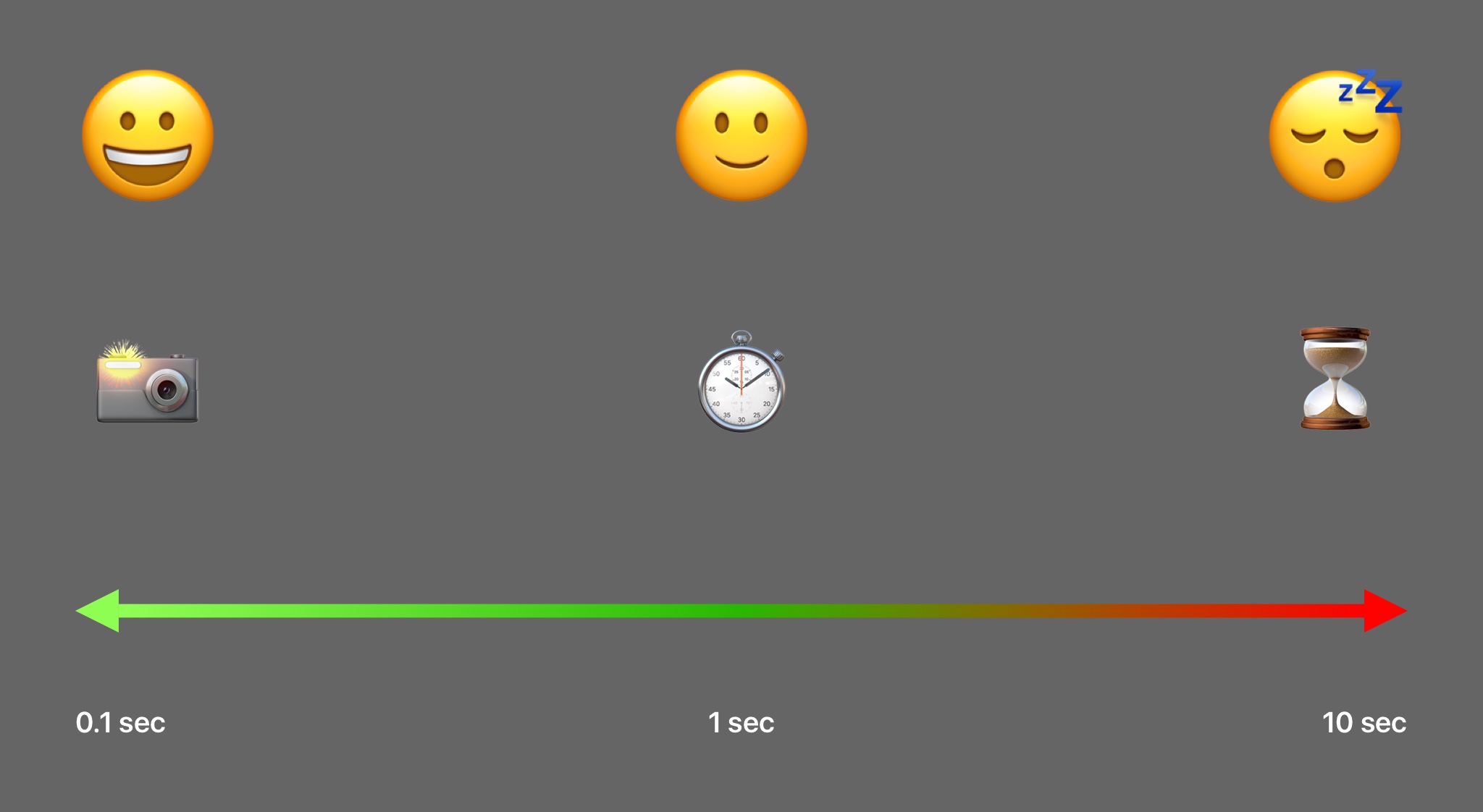
First, we had to understand as a team that this was a real issue. As Jakob Nielsen writes in his article Response Times about human-computer interaction, three time limits are crucial, and every interaction designer should know them:
-
0.1 second: Is about the limit for having the user feel that the system is reacting instantaneously.
-
1.0 second: Is about the limit for the user’s flow of thought to stay uninterrupted, even though the user will notice the delay.
-
10 seconds: Is about the limit for keeping the user’s attention focused on the dialogue.
The closer a response is to the 0.1 barrier, the more instantaneous it feels. The further away a response is from the 1.0 barrier, the more sluggish it will feel.
 Everybody wants to be happy
Everybody wants to be happy
After sharing this fact, I needed data points to show how slow the recognition was. I needed to come up with a simple and pragmatic way to do that without stressing out developers and binding their resources. So, I recorded the speech recognition with screen recording software, or I just took a video of two or three smartphones with DIVA and other voice recognition software next to each other.
Then I replayed the recording and counted the frames between the uttering of word and the word being displayed on the screen. Then I just needed to calculate the seconds based on the fps of the video file. I would do that with two different sentences every now and then. All competitive voice recognition software was faster than 1.0 second, with Google being the fastest. DIVA with up to 3 seconds was way behind. Fixing this was not an easy task. There are different systems that work together and different reasons why it was taking longer for DIVA.
Teamwork
Every time I did the test I shared the results in our weekly meetings and asked the team what we could do about it. The engineers came up with ideas. After those were deployed, I tested again and shared the results. It was important to keep working on the issue continuously. It is only when a problem haunts you that you think about solutions. To ensure this was the case, the team needed to be made aware of the issue. The process went on for nine months. Not every change we deployed made it better. But every change meant we were trying, and gave us a new way of looking at things.
The engineers also would come up with ideas for simple visual indicators that the system was working or for debugging techniques so the user could see on the screen when something was stuck.
350% Faster
Nine months later we broke the 1.0 second barrier. It took DIVA only 0.6 seconds until an uttered word was displayed on the device. That was 350% faster than when we started (2.7 seconds). We were even faster than Apple Siri, and nearly as fast as Google speech recognition. This was a big achievement for the team.
Retrospect
Design is not how it looks, but how it works. And only close teamwork between engineering and design can make the dream work.